
HybridClaw Documentation
Observability for AI Agents
Metrics taxonomy, KPIs, cost & safety telemetry — built into the runtime, not bolted on.
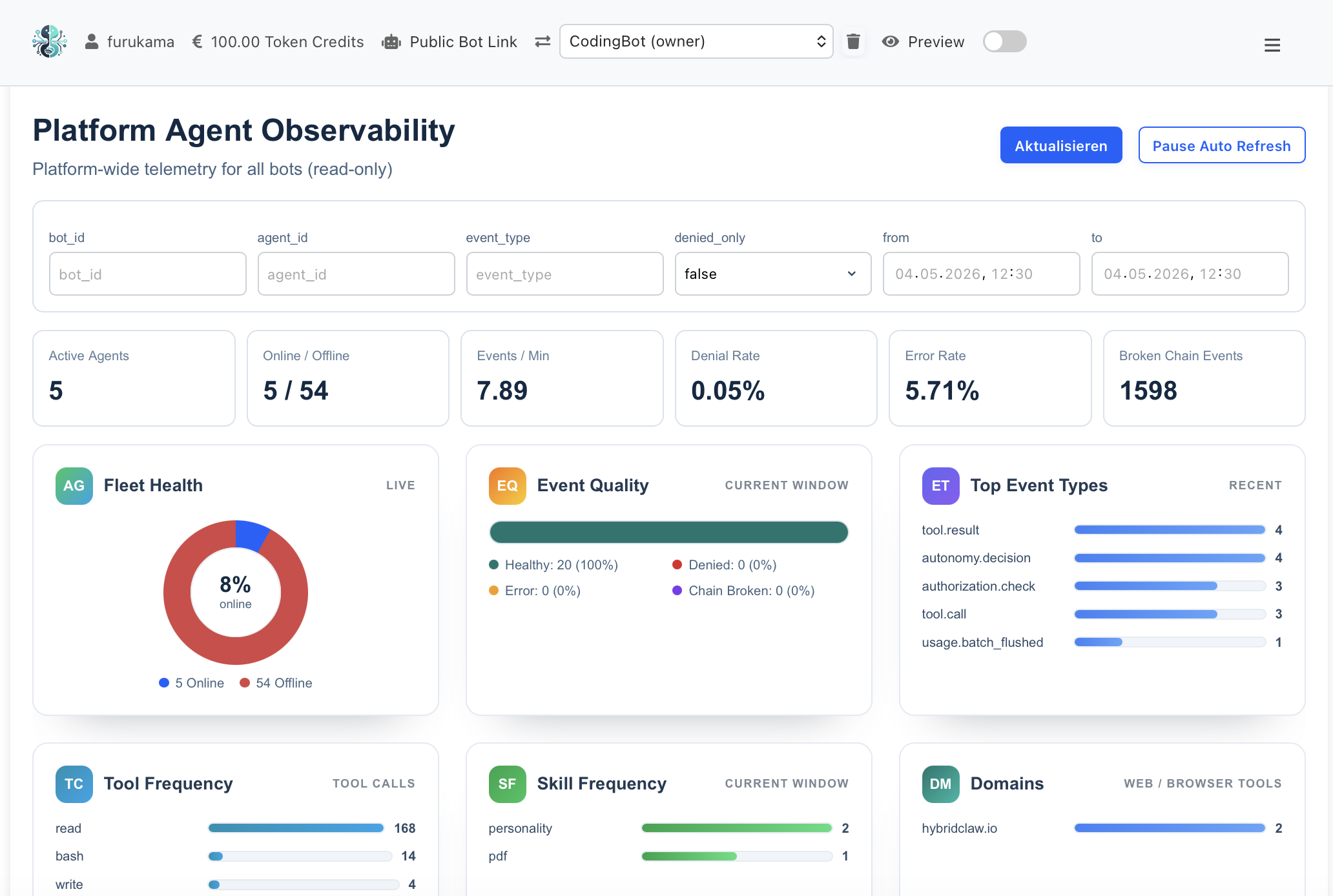
Live Monitoring Dashboard — Gateway, Agent & Execution Spans
Metrics Taxonomy
Every span, every tool call, every model invocation emits structured telemetry. The taxonomy is stable, documented and consistent across agents — so dashboards, alerts and SLOs work the same way for every team.
| Metric | What it measures | Aggregation | Typical alert threshold |
|---|---|---|---|
| task.latency_ms | Wall-clock duration from task arrival to terminal state. | p50, p95, p99 per skill | p95 > 2x baseline |
| task.cost_eur | Total cost (model + tools) per task in EUR. | Sum per agent / skill / day | Cost-per-task > budget |
| task.tokens_in / tokens_out | Input + output tokens per LLM call. | Sum per model | Sudden 50% increase WoW |
| eval.score | Score from regression eval against task-specific test cases. | Min, mean per skill version | Score drop > threshold blocks deploy |
| safety.flag_rate | Fraction of tasks flagged by safety classifier. | Rolling 1h, 24h | > baseline + 2σ |
| tool.error_rate | Fraction of tool calls returning an error. | Per tool, rolling 5m | > 5% sustained |
| human_handoff.rate | Fraction of tasks escalated to human approval. | Per skill, daily | Sudden change indicates skill drift |
| skill.regression_delta | Eval-score change after skill or model update. | Per deploy | Negative delta blocks promotion |
KPIs Operators Actually Use
Per-call metrics are useful for debugging. KPIs are what you put in front of a sponsor or board to show whether the agent program is paying off.
Cost per resolved task
Total spend (model + tools + human review) divided by tasks reaching a terminal success state. Compares directly to human-only baseline.
Mean time to human escalation
How long agents work autonomously before a task is handed off. Rising = skill drift; falling = improving autonomy.
Skill regression delta after deploy
Eval-score change between current and prior skill version. Catches model upgrades that silently degrade behavior.
Human-approval acceptance rate
Fraction of agent-proposed actions that humans accept. Low rate = poor judgment; rate of 1.0 over time = trust threshold reached, automate the gate.
Safety incident rate
Flagged outputs per 1000 tasks. Tracked per channel and skill — used to catch new prompt-injection or jailbreak patterns.
Time to first useful output
From channel message in to first useful agent response. The user-facing latency that determines whether agents feel real-time.
Reliability — Evals as a Deploy Gate
Models change. Skills get edited. Without an eval gate, every deploy is a coin flip. HybridClaw records real task runs as trajectories, replays them against new skill or model versions, and surfaces regressions before they reach production.
-
Trajectory replay. Past runs become test cases. New versions must match or beat the score.
-
Skill scorecards. Per-skill dashboard shows pass-rate, latency and cost across the eval set. Operators can see at a glance whether a skill is production-ready.
-
Deploy gate. Configurable thresholds — score, latency, cost — block promotion automatically. No human in the deploy loop unless a regression actually appears.
-
Content-addressed rollback. Every skill version is content-addressed. Rollback is one command, deterministic, and auditable.
Cost Control
Agent platforms can burn through model budgets fast. HybridClaw makes cost a first-class observable metric — measured per agent, per skill, per task — and exposes the levers operators need.
Model routing
Send simple tasks to cheaper models, complex ones to capable ones — based on cost-per-quality measured by evals.
Per-agent budgets
Soft and hard caps per day / week / month. Soft cap warns, hard cap stops new tasks until lifted.
Cache layers
In-memory, on-disk and shared cache for skill outputs and retrieval. Cache hits cost nothing.
Trajectory pruning
Skills that consistently exceed token budgets are flagged for refactoring or context compression.
Cost reports
Daily / weekly cost reports per agent and skill, exportable as CSV.
Cost-per-outcome KPI
Track total spend against business outcomes (resolved tickets, generated leads, etc.) — not just raw token consumption.
Safety Telemetry
Safety is not an output filter — it is a continuous signal in the same telemetry stream as latency and cost. Operators see safety incidents alongside the actions that caused them, with full audit trail.
- Every flagged output is logged with the trajectory that produced it — so post-incident review takes minutes, not days.
- High-impact actions (transfers, external mails, deletes) require human approval — configurable per skill, audit-logged.
- Tamper-evident audit log: every action chained and content-addressed. Operators can prove what an agent did, when, and on whose authority.
- EU-hosted control plane. GDPR & AI-Act compliant by design.